
Over the past few months, Whitehead Communications has been testing out several new communications research techniques to see the bigger picture when it comes to public opinion. One of these was employing a novel machine learning technique called LDA Topic Modelling to analyse how the Ugandan online media has been covering Covid-19, which was led by our research teammate Joyce Yanru Jiang. We decided to use tailored Python code to scrape Ugandan news media websites collecting thousands of articles including the keywords "covid" or "corona" and then run them through a LDA Topic Modelling algorithm, testing out different parameters until we were able to confidently identify a range of sub-topics included in the Ugandan media's stories related to the coronavirus pandemic.
In the course of our research, we learned that there is a group at Boston University's Hariri Institute for Computing and Computational Science and Engineering that is applying a similar technique to analyse Covid-19 news in other countries, so we got in touch and had a couple Zoom meetings, as one does in 2020. Their code and sourcing methods were a little different than ours, but we decided to collaborate by updating our dataset and processing it through their method.
Our new Topic Model in collaboration with the team at Boston University (BU) can be found at this link.
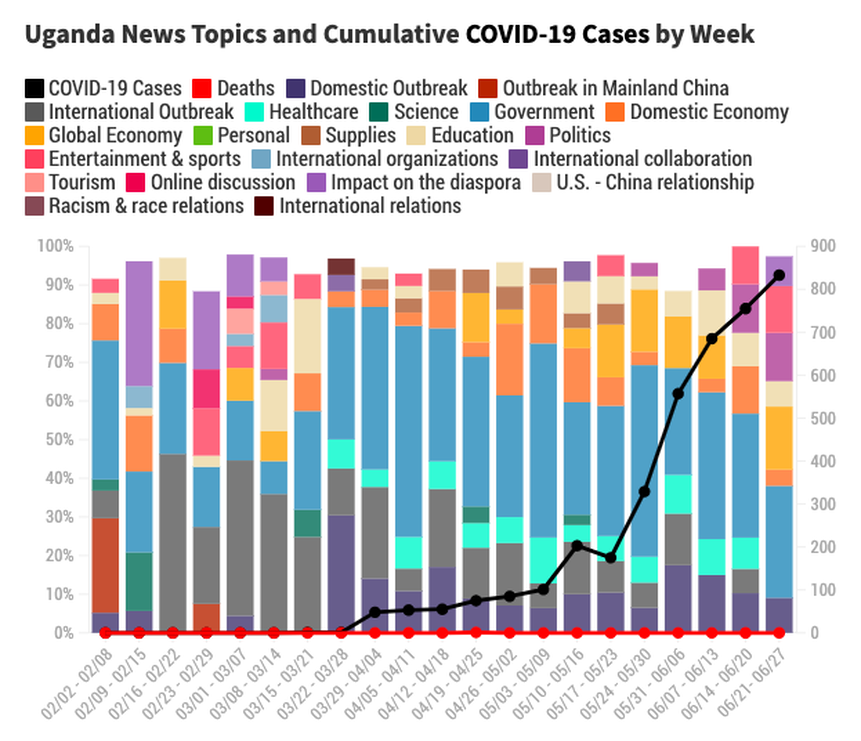
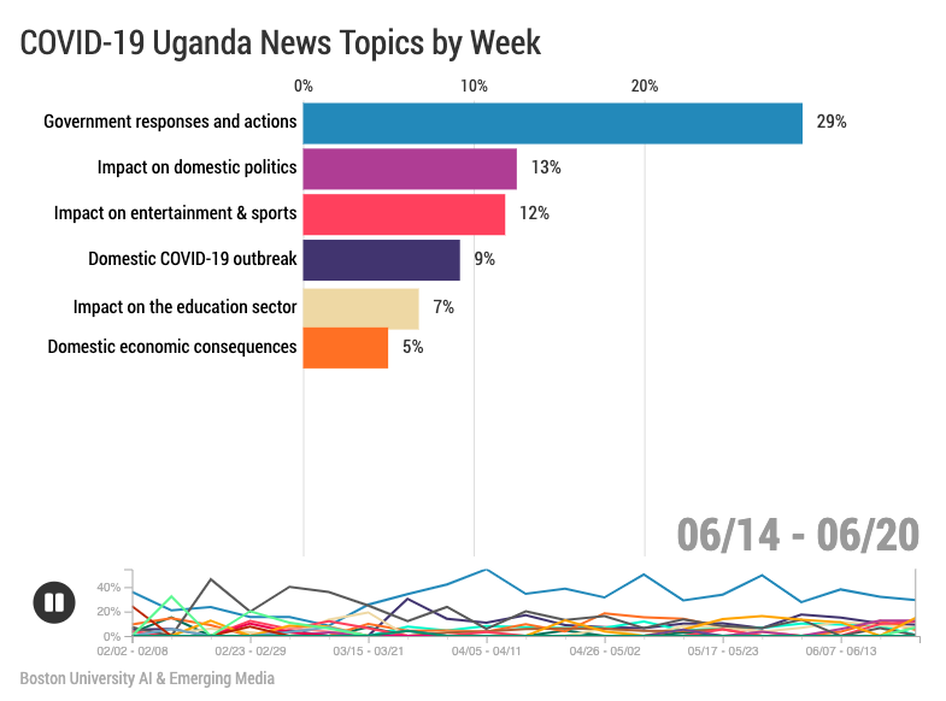
We're grateful to Dr. Lei Guo and the team at Boston University for their guidance and their very cool racing bar graph (in the link above) that shows how news topics changed over time.
For those who would appreciate more detailed notes on methodology: the differences between our model (which I'll call the Whitehead-Jiang model) in our earlier topic modelling report and the BU model are as follows.
1. We included additional TV and radio news from the web pages of NTV, UBC and KFM in our BU model, which resulted in a larger dataset of 14,947 news articles.
2. We applied BU's model to our dataset, which was based on a Mallet NLP tool kit, though we modified it slightly for the Ugandan context by adding stop words and paired words to improve accuracy.
3. The Whitehead-Jiang model processed the full text of articles, but the BU model only used headlines and lead paragraphs, so for the sake of consistency, we only used this shorter form dataset in our application of the BU model.
4. The BU model was run on each week of data separately, unlike the Whitehead-Jiang model, which processed all data from start to finish together.
5. We identified topics in our BU model by applying BU's recommended topics as used in other countries, and we adjusted them where necessary to the Ugandan context. This process was verified by our Ugandan team Owilla Mercy and Norman Angel.
6. Note that our dataset from Uganda was the only country included in BU's research that offered full text of articles because we scraped them manually instead of using a news database. This has made it possible for our data to be used in a second BU project analysing news framing. We also found that full text is preferable for checking the relevancy of the data thereby training better models.
This has been a great learning experience for us and we look forward to collaborating more with Boston University and other researchers around the world, as well as applying this technique to other projects in the future!
For more information on this or to enquire about working together, please contact me Anne Whitehead at [email protected]
